
We zijn al best ver gekomen. Maar we zijn er nog niet.
In het vorige deel hebben we de twee activities geschreven die de namen van de usergroups ophaalt en vervolgens een bericht stuurt naar die groepen met het email adres van de bezoeker. We konden de berichten parallel versturen, de code ging pas verder nadat we alle berichten verzonden hadden.
Tenminste, zo leek het.
We weten nu dat het eigenlijk anders werkt. Na iedere aanroep van een activity gaat de orchestrator weg om daarna weer in het leven geroepen te worden, waarna we via een replay alles opnieuw uitvoeren. Nou ja, alles.. de activities niet: alleen het resultaat wordt opgehaald. Nu is dit de prijs de we moeten betalen voor een durable omgeving in een stateless, serverless omgeving. En de penalty is ook niet zo hoog. Maar: stel dat we honderden usergroups zouden willen verwittigen, gevolgd door honderden notificaties dat iedereen akkoord gaat. Dan krijgen we heel veel replays.
Kijk eens naar de Storage Explorer, na een run van onze relatief kleine workflow:
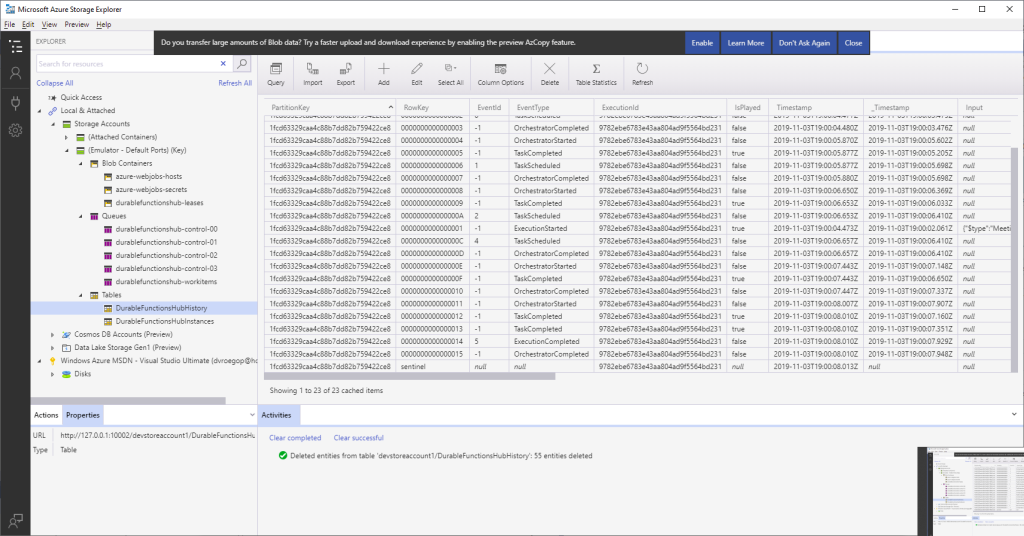
De hoeveelheid data in deze tabel kan snel heel groot worden. Dat geeft niet, maar dat betekent ook dat de replays steeds langer duren. Daar is een oplossing voor. We kunnen delen van de orchestration er uit halen en in een nieuwe orchestration zetten. Deze orchestration draait zelfstandig en krijgt ook een eigen InstanceId, alsof het een totaal nieuwe orchestration is. Dat is het dan ook.
Dus: voor de hoofd orchestration is de sub-orchestration iets als een activity, in de sub-orchestration is het een echte orchestration. Klinkt als een win-win situatie, niet waar? Laten we dat dan maar bouwen!
Refactoring van de orchestration
Als we de hoeveelheid replays willen beperken, zullen we de stukken code die vaak herhaald worden uit de hoofd method moeten halen. In ons geval is dat de code die door de lijst van usergroups heen gaat en daar dan berichten heen stuurt. Maar: voor die lus staat een call naar een andere activity: het ophalen van de usergroups. Wat doen we daar mee? Gaan we die naar de sub-orchestration verhuizen? Dan wordt hij iedere keer als we een bericht naar een usergroup sturen aangeroepen. Nou ja… niet echt aangeroepen: het resultaat wordt opgehaald. Maar het is wel weer een extra entry in de tabellen. En dat voor iedere usergroup.
Aan de andere kant: hij hoort functioneel wel echt bij de code die die berichten verstuurd. Dus wat dat betreft moet hij in de suborchestration.
Het is een keuze die je moet maken. Ik kies voor leesbaarheid en overzichtelijkheid in mijn code. Die tabel zal ik toch niet veel lezen dus als daar wat meer data in komt vind ik dat wel prima.
Laten we de code voor het versturen van de notificaties maar eens refactoren en in een aparte method zetten:
private static async Task NotifyAllUserGroups(DurableOrchestrationContext ctx, ILogger log, Attendee attendee)
{
if (!ctx.IsReplaying)
log.LogWarning("Getting all usergroups.");
var allUsergroups = await ctx.CallActivityAsync<string[]>("A_GetUsergroupNames", null);
var allCalls = new List<Task>();
foreach (var usergroupName in allUsergroups)
{
var notification = new UsergroupNotification
{AttendeeEmail = attendee.Email,
UsergroupName = usergroupName
};
allCalls.Add(ctx.CallActivityAsync("A_NotifyUsergroup", notification));
}
await Task.WhenAll(allCalls);
}
En uiteraard in de orchestrator method roep ik deze aan na de aanroep na ValidateInput() en voor het einde. Affijn, je weet wel wat refactoren is:
Nu is dit geen suborchestration. Deze method is nog steeds onderdeel van de hoofd orchestration. Dus ik ga hem even herschrijven:
[FunctionName("O_NotifyAllUsergroups")]
public static async Task NotifyAllUsergroups([OrchestrationTrigger] DurableOrchestrationContext ctx, ILogger log)
{
if(!ctx.IsReplaying)
log.LogWarning("Calling all usergroups");
var attendeeEmail = ctx.GetInput<string>();
var allUsergroups = await ctx.CallActivityAsync<string[]>("A_GetUsergroupNames", null);
var allCalls = new List<Task>();
foreach (var usergroupName in allUsergroups)
{
var notification = new UsergroupNotification { AttendeeEmail = attendeeEmail, UsergroupName = usergroupName };
allCalls.Add(ctx.CallActivityAsync("A_NotifyUsergroup", notification));
}
await Task.WhenAll(allCalls);
}
Dit is al een heel stuk beter. Ik heb er nog even een log bij gezet die alleen aangeroepen wordt als we niet aan het replayen zijn.
Het is een nieuwe orchestrator functie (snap je nu waarom ik de static class OrchestratorFunctions genoemd heb?)
Ik ga de email van de attendee meegeven (weet je nog: micro services krijgen niet meer data dan wat ze nodig hebben, dus ik ga niet de hele attendee meegeven). Ik haal die attendee email op uit de context. Dan haal ik de usergroups op in de activity A_GetUsergroupNames. Vervolgens maak ik de lijst met Tasks aan, geef deze de nieuwe activities mee en uiteindelijk roep ik alles aan met Task.WhenAll();
In mijn hoofd-orchestrator vervang ik de call naar de gerefactorde method met de volgende call:
await ctx.CallSubOrchestratorAsync("O_NotifyAllUsergroups", attendee.Email);
Ik gebruik de method CallSubOrchestratorAsync en geef de naam van de nieuwe orchestrator en de email mee.
Als ik dit aanroep, zal de orchestrator, net als bij de activities, weer uit het geheugen gaan. We komen pas weer terug in de orchestrator als de suborchestrator klaar is. Net als bij de activities dus.
De suborchestrator doet zijn ding op dezelfde manier als de hoofd orchestrator: zo gauw je een activity aanroept verdwijnt hij uit het geheugen, komt terug vanaf het begin en gaat het resultaat uitlezen van die activity. Je kent het nu wel.
Het mooie is dat deze sub-orchestrator nu steeds herhaalt wordt voor iedere usergroup. De log wordt maar een keer weggeschreven dankzij de call naar ctx.IsReplaying. De hoofd orchestrator echter blijft wachten.
Als we dit gaan draaien en we kijken in de TableStorage, dan zien we dat de suborchestration inderdaad een andere instance Id krijgt. Het kan zelfs zo zijn dat deze suborchestration op een hele andere VM draait, of zelfs in een andere regio. We zijn nog steeds stateless en serverless en dus schaalbaar, maar we zijn wel een stuk overzichtelijker geworden.
Als je nu meerdere suborchestrators parallel wilt draaien, kun je hetzelfde trucje uithalen als we vorige keer deden: niet await aanroepen bij ctx.CallSubOrchestratorAsync maar deze opslaan in een lijst en die dan met Task.WhenAll laten uitvoeren. Cool he!
Next step
Dit is allemaal leuk en prima, maar wat als een workflow nu handmatige stappen kent? Hoe gaan we daar mee om? Veel workflow engines hebben daar iets voor, iets wat er voor zorgt dat de flow gepauzeerd wordt tot iemand of iets zegt dat we verder kunnen. Met Durable Functions kan dat ook. Hoe? Dat zien we in de volgende twee posts.
